
#11 Subqueries
SQL Crash Course #11


All the course material is stored in the SQL Crash Course repository.
Hi everyone! Cornellius and Josep Ferrer from DataBites here 👋🏻
As promised, today we are publishing the next two issues of our SQL Crash Course – From Zero to Hero! 🚀
I am sure you are here to continue our SQL Crash Course Journey!📚
If this is your first time or you’ve forgotten what we’ll cover, we will examine seven key SQL topics, each divided into multiple posts across Non-Brand Data and DataBites.
📚 Previously in SQL Basics…
Remember last Thursday we already saw:
📌 #9 – Case Expressions
📌 #10 – Functions (String, Date, Numeric)
Today, we will explore an exciting new topic in our SQL learning:
Advanced SQL🤩
In today’s topic, we have two new brand issues:
📌 #11 – Subqueries: the course you are currently learning, we will explore how to work with nested queries.
📌 #12 - Common Table Expressions (CTEs): Josep Ferrer in DataBites will teach you methods to structure and organize your SQL queries.
So don’t miss out—let’s keep the SQL momentum going!
🧱 What is a Subquery?
A query-within-a-query that returns:
Single value (Scalar)
Multiple values (List)
Full table result
Basically, a subquery is a complete SQL query nested inside another query.
Subqueries often follow the following format:
SELECT main_column
FROM main_table
WHERE main_column IN (
SELECT filtered_column
FROM secondary_table
WHERE condition
);You can see that the above subqueries attempt to find specific data based on conditions from another table. This is one of the uses of subqueries, but it encompasses much more than that.
So, ✅ When to Use Subqueries:
👉When you want to break complex problems into steps
👉When you want to compare values to aggregate metrics
👉When you want to filter based on another table's contents
👉When you want to create temporary calculation tables
That’s the common usage, but it encompasses much more than that. It largely depends on your use cases.
Let’s see SQL Subqueries in action!👇
1️⃣Preserve Original Table Structure
Real-world scenario:
"Show newsletter details with interaction counts without altering original columns"
Without subqueries, you'd need to:
SELECT
n.id,
n.name,
COUNT(p.id) AS total_posts
FROM newsletters n
LEFT JOIN posts p ON n.id = p.newsletter_id
GROUP BY n.id, n.name;With subqueries (SELECT clause):
SELECT
n.id,
n.name,
(SELECT COUNT(*)
FROM posts p
WHERE p.newsletter_id = n.id) AS total_posts
FROM newsletters n;🧠 Why Subquery: Maintains 1:1 newsletter records while adding calculated metrics without JOIN expansion or GROUP BY needed are beneficial:
Maintains 1 row per newsletter (no GROUP BY)
Easier to add multiple calculated columns
No risk of duplicate newsletter records
2️⃣ Aggregate Comparisons
Real-world scenario:
"Find posts with total interaction points > average"
Without subqueries, you can use CTE (which we will learn in the next post):
WITH post_totals AS (
SELECT
post_id,
SUM(points) AS total
FROM interactions
GROUP BY post_id
)
SELECT p.name, pt.total
FROM posts p
JOIN post_totals pt ON p.id = pt.post_id
WHERE pt.total > (SELECT AVG(total) FROM post_totals);With subqueries (WHERE or HAVING clause) :
SELECT
p.name,
SUM(i.points) AS total_points
FROM posts p
JOIN interactions i ON p.id = i.post_id
GROUP BY p.id
HAVING SUM(i.points) > (
SELECT AVG(total)
FROM (
SELECT SUM(points) AS total
FROM interactions
GROUP BY post_id
) agg
);🧠 Why Subquery: Compares aggregated post totals against a dynamic average calculated from all interactions having their benefit:
Single query vs multiple CTE steps
No temporary tables needed
More readable for simple comparisons
3️⃣ Multi-layer Calculations
Real-world scenario:
"Compare post interaction points to their newsletter's average"
Without Subqueries, it might be harder to control individual components:
SELECT
p.name AS post_name,
p.newsletter_id,
SUM(i.points) AS post_points,
AVG(SUM(i.points)) OVER (PARTITION BY p.newsletter_id) AS avg_points
FROM posts p
JOIN interactions i ON p.id = i.post_id
GROUP BY p.id, p.newsletter_id;With subqueries (FROM clause):
SELECT
p.name AS post_name,
p.newsletter_id,
SUM(i.points) AS post_points,
newsletter_avg.avg_points
FROM posts p
JOIN interactions i ON p.id = i.post_id
JOIN (
SELECT
newsletter_id,
AVG(points) AS avg_points
FROM posts
JOIN interactions ON posts.id = interactions.post_id
GROUP BY newsletter_id
) newsletter_avg ON p.newsletter_id = newsletter_avg.newsletter_id
GROUP BY p.name, p.newsletter_id, newsletter_avg.avg_points;🧠 Why Subquery: Creates a newsletter-level average dataset first, then joins for comparison, having a few benefits:
Clear separation of calculation layers
Easier to modify individual components
4️⃣ Existence Checks
Real-world scenario:
“Find newsletters that have at least 1 post named ‘DataBites’“
Without Subqueries, you might need to join everything to get the one you need:
SELECT DISTINCT n.*
FROM newsletters n
JOIN posts p ON n.id = p.newsletter_id
WHERE p.name = 'DataBites';With subqueries (EXISTS clause):
SELECT *
FROM newsletters n
WHERE EXISTS (
SELECT 1
FROM posts p
WHERE p.newsletter_id = n.id
AND p.name = 'DataBites'
);🧠 Why Subquery: Efficiently checks existence without returning duplicate newsletter records:
Better performance (stops at first match)
No need for DISTINCT
Clearer intent ("exists" vs "find matches")
For Conclusion….
The Key Locations & Why They Matter for the Subqueries:
1️⃣ WHERE Clause
Filter results using dynamic values from other tables
Example: Find posts with interaction counts exceeding the author's average
2️⃣ FROM Clause
Create intermediate tables for multi-step transformations
Example: Calculate regional averages from city-level data
3️⃣ SELECT Clause
Add contextual metrics without complex JOINs
Example: Show total company revenue next to department figures
4️⃣ HAVING Clause
Filter groups using aggregate comparisons
Example: Show product categories with sales 2x above average
💡 Pro Tip: Subquery vs JOIN
While they are often interchangeable, use subqueries when:
✅ Preserve original table structure (no added columns from JOINs)
✅ Work with aggregates in comparisons
✅ Build multi-layer calculations
✅ Handle "exists/doesn't exist" checks
👉Also, don’t miss the SQL Playground for this issue!
How to Get Started 🚀
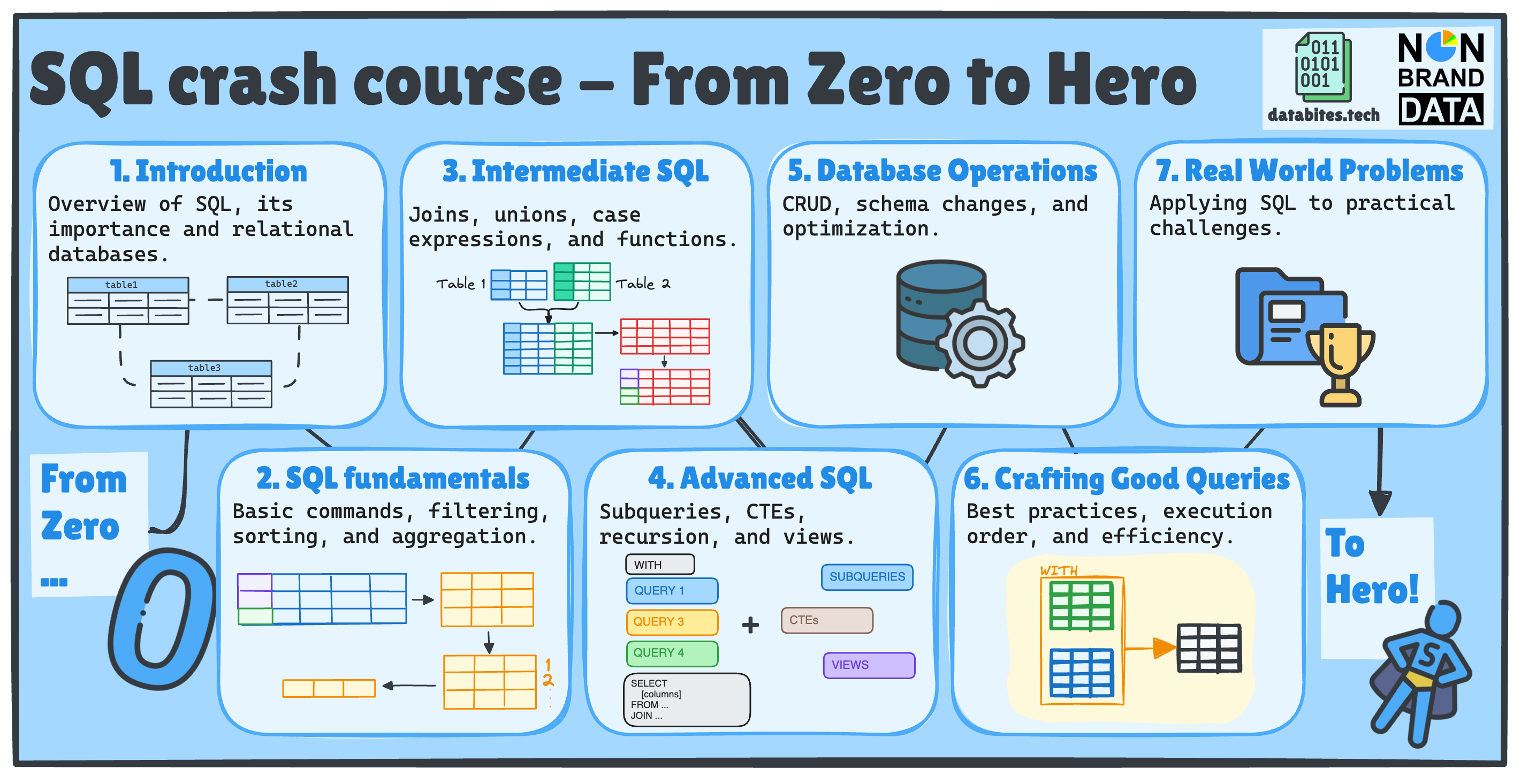
Over the coming weeks, we’ll guide you through:
✅ SQL Fundamentals
✅ Intermediate SQL
✅ Advanced SQL
✅ Database Operations
✅ Writing Efficient Queries
Once you grasp the basics, practice is key! Start working on real-world projects and solving hands-on data problems.
What’s Next? ➡️
This is the first of many posts about the upcoming SQL Courses. It will only explain what SQL is in its crude form.
To get the full experience and fully immersed in the learning:
👉 Subscribe to Databites.tech (By Josep)
👉 Subscribe to Non-Brand Data (By Cornellius)
👉 Check out the SQL Crash Course GitHub repo
👉 Share with your friend and whoever needs it!
🗓️ Every Thursday, you will have two new issues in your inbox!
Let’s dive in and make SQL less scary, more fun, and way more useful! 🚀
Josep & Cornellius