
Cohort Analysis for Assessing Group Behaviour - NBD Lite #35
Simple yet powerful technique for your business analysis


What is Cohort Analysis? An analysis was performed on the data group to assess its behavior.
Cohort analysis comes from the Cohort word, which means a group of people who have something in common — which implies that cohort analysis is an analysis of the group behavior.
Businesses often use cohort analysis to understand the customers' life cycle, especially over time.
For example, when you do a campaign or change the product, would it affect the revenue or retention — that is when you use the Cohort Analysis.
You want to analyze different cohorts better to understand the pattern and trend of the business target.
Let me give you an example in the image below.

You have customers who subscribe to your websites in June, July, and August.
You want to compare the customer retention rates after three months between different cohorts (customers in June, July, and August).
This is basically how cohort analysis compares the other groups of customers to your business needs.
Cohort Analysis Types
There are three types of Cohort Analysis depending on the cohort, they are:
Time-Based Cohort
This cohort analysis is similar to what I mentioned above and is the most used cohort. The analysis divides the data using different time frames to group it.
Time-based cohort analyses are useful for experiments that depend on time, for example, revenue over time, churn, offering, campaign, etc.
Segment-Based Cohort
Segment-based cohorts group the data into different groups based on the similarities and characteristics businesses have decided on. For example, we could do segment-based cohort analysis on customers’ products or log time.
The point of a Segment-based cohort is to see if the business is doing well based on this cohort. For example, if a customer who bought product X is less likely to buy another product than the customer who owns Product Y, then there is something that we could analyze.
Size-Based Cohort
Lastly, the Size-Based cohort groups the data by the size of the data group — of ten; it is divided by the Monetary value—for example, customers’ tier-level subscriptions or the customers’ business size.
Similar to the above, the size-based cohort is useful for assessing our business's performance among different customer levels. For example, customers who subscribe to higher tier levels are less likely to churn than those at the lower level.
Cohort Analysis Example
Let’s use a dataset example to understand how to do Cohort Analysis. In this example, I would use the Online Retail dataset from Kaggle. Let’s read the data first.
import datetime
import pandas as pd
df = pd.read_excel('Online Retail.xlsx')
df.head()
This dataset includes customer purchases in the Online store. Using the Cohort Analysis, we want to analyze the Retention rate of customers from their first purchase monthly.
This analysis means that what we do is a time-based cohort analysis. Let’s acquire the month when the transaction happened and group them based on the first month (CohortMonth).
def get_month(x): return datetime.datetime(x.year, x.month, 1)
df['InvoiceMonth'] = df['InvoiceDate'].apply(get_month)
grouping = df.groupby('CustomerID')['InvoiceMonth']
df['CohortMonth'] = grouping.transform('min')
df.head()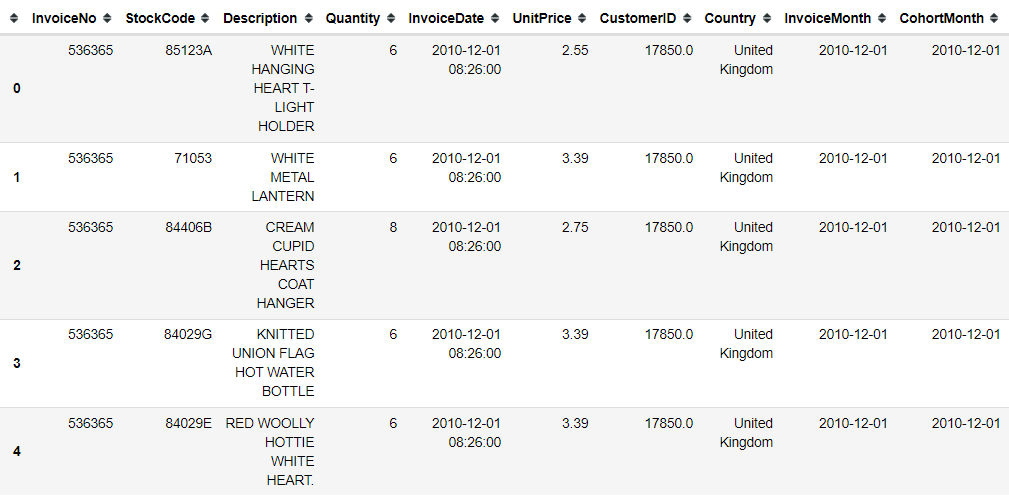
With the InvoiceMonth and CohortMonth columns, we would get the transaction month and the cohort month as the group.
Using this data, we need to get the differences between the transaction time and the cohort. Let’s obtain that data.
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
return year, monthinvoice_year, invoice_month= get_date_int(df, 'InvoiceMonth')
cohort_year, cohort_month = get_date_int(df, 'CohortMonth')years_diff = invoice_year - cohort_year
months_diff = invoice_month - cohort_monthdf['CohortIndex'] = years_diff * 12 + months_diff + 1
With month differences (CohortIndex) data, we could now group the data based on this month’s differences and calculate the Retention Rate of the Customers.
#Count the Customers who still rebuying from their first purchases
grouping = df.groupby(['CohortMonth', 'CohortIndex'])
cohort_counts = grouping['CustomerID'].apply(pd.Series.nunique).reset_index().pivot(index='CohortMonth',columns='CohortIndex',values='CustomerID')cohort_counts
Above is the Retention Customer count, but it is hard to analyze and doesn’t give us too much insight. We should plot this data and calculate it based on the percentage.
cohort_sizes = cohort_counts.iloc[:,0]
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.index=retention.index.dateplt.figure(figsize=(12,10))
plt.title('Retention Rates')sns.heatmap(data = retention,
annot = True,
fmt = '.0%',
vmin= 0.0,
vmax=0.5,
cmap='summer_r')
plt.show()
Above is the cohort count plotting results that we already transformed into percentages. As we can see, the customers from December 2010 have a better Retention rate overall, and the longer the customers have been with the Online store, the higher the retention rate is.
To conclude, Cohort Analysis is a statistical technique often used in the business to gain insight based on the group.
The analysis could calculate customer retention rate or revenue over time. There are three types of Cohort Analysis:
Time-Based
Segment-Based
Size-Based
That’s all my tips for learning about cohort analysis!
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
