


Cross-Validation to Improve Model Reliability
Basic model evaluation technique that we should understand.


Machine learning model development is only the beginning of any ML project. A crucial aspect of the project is the model evaluation.
Model evaluation is the process of assessing how effectively our model performs, especially to the unseen data. The reliability of the predictions to the unseen data is fundamental to the practical application of machine learning models. We can’t have an unreliable model in production as it hinders business activity.
However, we also need to ensure that the model performance result is not a product of overfitting. Overfitting occurs when a model learns the details and noise in the training data to the extent that it negatively impacts new data performance.
This is where cross-validation comes to help. Cross-validation is a robust technique to estimate the effectiveness of a model on unseen data. Unlike a simple train-test split or holdout method, cross-validation would involve multiple data partitioning into subsets, training on one subset, and validating the results on another.
Cross-validation would improve the reliability of model evaluation by offering a more comprehensive view of a model's predictive power. That’s why it’s essential to understand the power of cross-validation.
In this newsletter, we will run through some of the Cross-validation techniques and the code implementation. Let’s get into it.
K-Fold Cross-Validation
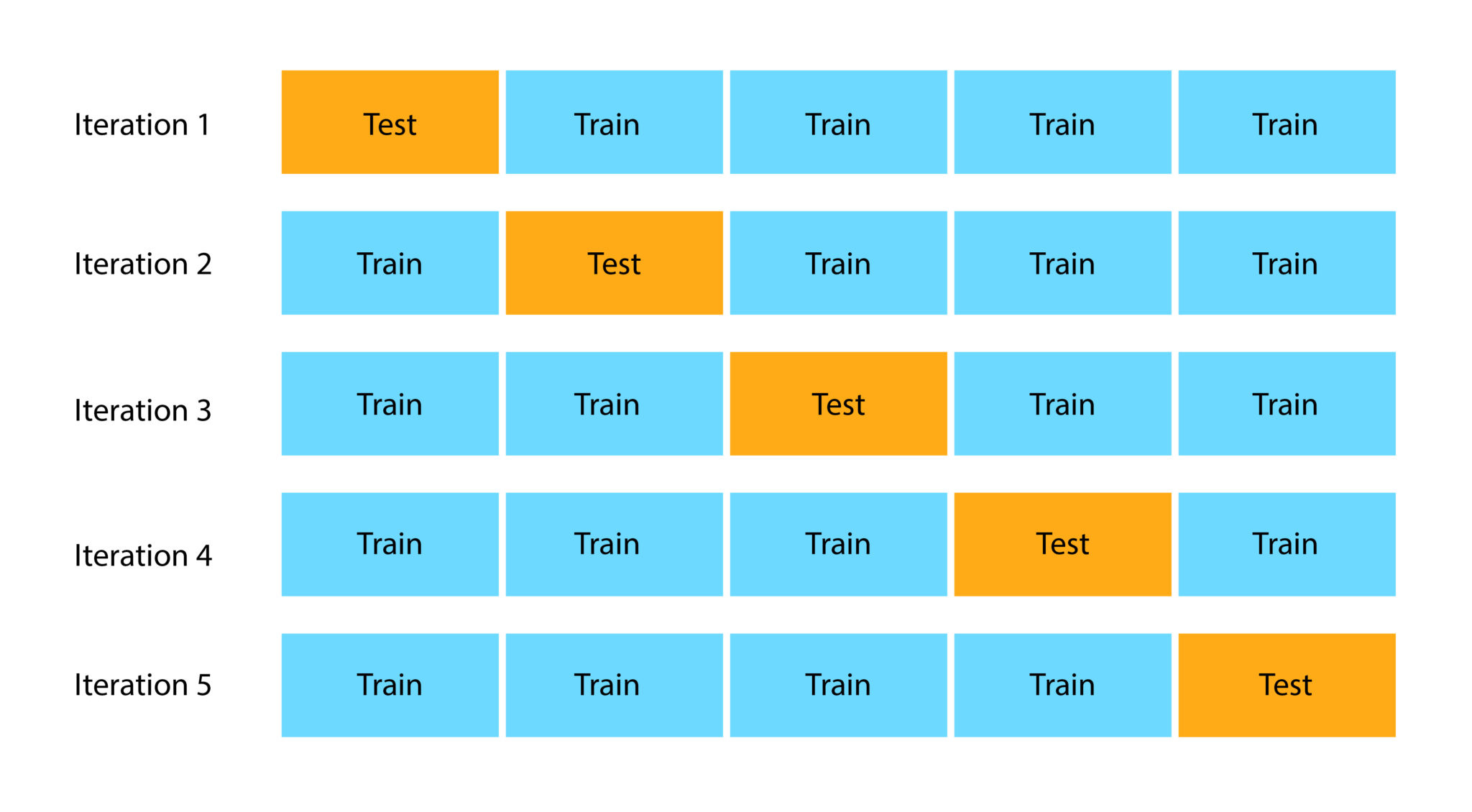
K-Fold Cross-Validation is the model evaluation technique that divides the dataset into K equal parts, where K is an integer number.
In each round of validation, one of these parts is used as the test set, and the remaining K-1 folds are combined to form the training set. This process repeats K times, with each fold used exactly once as the test set. The final model performance is typically the average of the K test results.
This method ensures that every data point is used for training and testing, mitigating the risk of performance variance due to data split. The technique can provide a more reliable and stable estimate of model performance compared to the Holdout method, as it reduces the influence of random data splits on the model's performance evaluation.
However, there are disadvantages to relying on this technique. The primary drawback of K-Fold Cross-Validation is its increased computational cost. Running the K training and evaluation cycles can be time-consuming and requires high computing resources, especially for large datasets and complex models.
The choice of K could also impact the results. Too small a value might be close to the Holdout technique, while too large a value increases computation time and may lead to models overfitting particular data.
To perform K-Fold Cross-Validation, you can use the following code.
from sklearn.model_selection import cross_val_score, KFold
#Initiate the kfold
kf = KFold(n_splits=5, shuffle=True, random_state=101)
scores = cross_val_score(model, X, y, cv=kf)Stratified K-Fold Cross-Validation
Stratified K-Fold Cross-Validation is a variation of the K-Fold method designed to handle imbalanced datasets. It ensures that each fold of the dataset contains approximately the same percentage of samples of each class as the original dataset. This technique is essential in scenarios where imbalance data exists, which can skew the training and, thus, the evaluation of a model.
By preserving the original class distribution in each fold, the Stratified K-Fold provides a more reliable and unbiased estimate of model performance. It's beneficial in classification problems where maintaining the proportion of classes is important for an accurate evaluation.
However, the Stratified K-Fold is not very useful in the regression tasks. Implementing this method requires more careful planning and understanding of the dataset's structure.
We can apply Stratified K-Fold by using the following code.
from sklearn.model_selection import StratifiedKFold
#Initiate Stratified k-fold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=101)
scores = cross_val_score(model, X, y, cv=skf)Leave-One-Out Cross-Validation (LOOCV)
LOOCV is a specific form of cross-validation where the number of folds (K) equals the number of observations in the dataset. This means that for a dataset with N data points, LOOCV involves creating N different training sets and N different testing sets.
In each iteration, one observation is held out as the test set, and the remaining N-1 observations are used as the training set. This process is repeated N times, with each data point used as the test set exactly once.
This method provides a comprehensive assessment of the model's performance. By using nearly all the data for training and testing the model on a single data point, LOOCV can give a detailed insight into how the model performs across different subsets of the data.
Because the training set in each iteration is nearly as extensive as the entire dataset, the bias of the model evaluation is typically lower compared to other methods like K-Fold Cross-Validation.
However, LOOCV can be highly computationally demanding, requiring fitting the model N times, especially for datasets with many observations. Additionally, the variance of the model evaluation can be high and can be sensitive to outliers.
You can perform LOOCV with the following code.
from sklearn.model_selection import LeaveOneOut
# Initiate Leave-One-Out Cross-Validation
loo = LeaveOneOut()
scores = cross_val_score(model, X, y, cv=loo)Nested Cross-Validation
Nested Cross-Validation (NCV) is an advanced technique used primarily for model selection and hyperparameter tuning.
It consists of two layers of cross-validation: the inner loop and the outer loop. The outer loop assesses the model's performance, while the inner loop selects the model and tunes its hyperparameters.
In the inner loop, a subset of the data (the training set from the outer loop) is used for hyperparameter tuning. This can be done using methods like Grid Search or Random Search. The inner loop performs standard cross-validation, such as K-Fold, on this subset to determine the best hyperparameters for the model. It ensures that the test data in the outer loop remains completely unseen during this tuning process.
The outer loop is then used to evaluate the model's performance. It splits the data into training and test sets. The model that has been hyperparameters tuned in the inner loop is then trained on the training set of the outer loop and evaluated on the test set. This process is repeated with different data splits, typically using K-Fold cross-validation.
The method could avoid bias and allow for robust model selection. However, the technique could be computationally expensive and require careful handling of data separation.
We can perform the NCV with the following code.
from sklearn.model_selection import GridSearchCV
# Example of hyperparameter tuning parameter
param_grid = {'C': [0.1, 1, 10, 100]}
# Inner loop CV for parameter tuning
inner_cv = KFold(n_splits=5, shuffle=True, random_state=101)
grid_search = GridSearchCV(model, param_grid, cv=inner_cv)
# Outer loop CV for model evaluation
outer_cv = KFold(n_splits=5, shuffle=True, random_state=101)
scores = cross_val_score(grid_search, X, y, cv=outer_cv)
Time Series Cross-Validation
Time Series Cross-Validation is a technique for time-dependent data where the order of observations is crucial. Unlike standard cross-validation methods, which randomly shuffle and split data, Time Series Cross-Validation maintains the chronological order of the data.
Usually, the method involves progressively expanding the training dataset and using the next time step as the test set. This method can take the form of a rolling-window or an expanding-window approach. In the rolling-window, the window of training data rolls forward in time (keeping the size constant), while in the expanding-window, the size of the training set increases over time.
We can perform the Time Series Cross-Validation with the following code.
from sklearn.model_selection import TimeSeriesSplit
# initiate the Time Series Split
tscv = TimeSeriesSplit(n_splits=5)
scores = cross_val_score(model, X, y, cv=tscv)Conclusion
Cross-validation is a technique that is important to measure model performance reliability. Using the method, we can ensure that our model serves the best prediction compared to the standard holdout method. In our discussion, we talk about the following technique:
K-Fold Cross-Validation
Stratified K-Fold Cross-Validation
Leave-One-Out Cross-Validation (LOOCV)
Nested Cross-Validation
Time Series Cross-Validation
Thank you, everyone, for subscribing to my newsletter. If you have something you want me to write or discuss, please comment or directly message me through my social media!