


Easy Automated Feature Engineering For Machine Learning Model
Automate the painful part of the model development

Automate the painful part of the model development

As a Data Scientist, we know that working with data is our everyday activities. From pulling the data, analyze the data, and create a useful machine learning model.
While many thought that creating a machine learning model is easy, the reality says otherwise. People might think that we only need to type some coding language and voila! The machine learning model is done.
It might work like that, but would the model useful and have any impact on the business problem? Most of the time probably isn’t. This is because the data in real life is messy, and without proper measurement, it would lead to a flawed model.
One of the proven ways to increase the machine learning model performance is by creating new features from existing features or feature engineering.
The feature engineering concept is easy to understand, as the idea is about creating new features from existing features. e.g., We have the data of product prices with their weight.
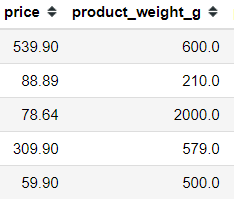
From these two features, we could create a new feature. Let’s say the product price per gram. In that case, we need to divide the price by the product weight.
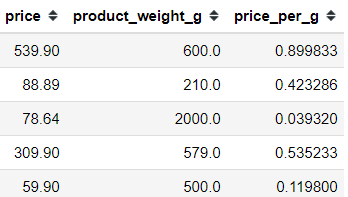
Just like that, we get a new feature. This is the concept of feature engineering.
The heart of the machine learning model is the data, and the way to increase the performance is by Feature Engineering, although it takes many skills to master Feature Engineering. We need to be creative and understand the business domain. It certainly would take a lot of time.
To solve the partial part of the feature engineering problem, we can automate the time-tasking feature engineering process.
Automated Feature Engineering
One of the major open-source library for performing automated feature engineering is Featuretools. It is a library designed to fast-forward the feature generation process by automating the process.
In Featuretools, there are three major components of the package that we should know. They are:
Entities
Deep Feature Synthesis (DFS)
Feature primitives
The explanation is in the below passage.
The Entity is a representation of a Pandas DataFrame in the Featuretools. Multiple entities are called an Entityset.
Deep Feature Synthesis (DFS) is a Feature Engineering method from the Featuretools. This is the method used for the creation of new features from single and multiple data frames.
DFS creates features by applying Feature primitives to the Entity-relationships in an EntitySet. Feature primitives are what we called methods to generate features manually e.g., the primitive mean would be a mean of a variable at an aggregated level.
That is enough theory; we might just jump to the real usage of the tools. For preparation, we need to install the library first.
pip install featuretoolsNow, Featuretools are best to use with multiple datasets with many relations. In this case, I would use the Olist Brazallian E-Commerce Dataset from Kaggle.
The data is in the CSV Files and consisted of many data. In this case, I would select a few data as examples.
olist_items = pd.read_csv('olist_order_items_dataset.csv')olist_product = pd.read_csv('olist_products_dataset.csv')olist_customer = pd.read_csv('olist_customers_dataset.csv')olist_order = pd.read_csv('olist_orders_dataset.csv')Let’s take a look at the data in brief. First, let’s take a look at the olist_customer data.
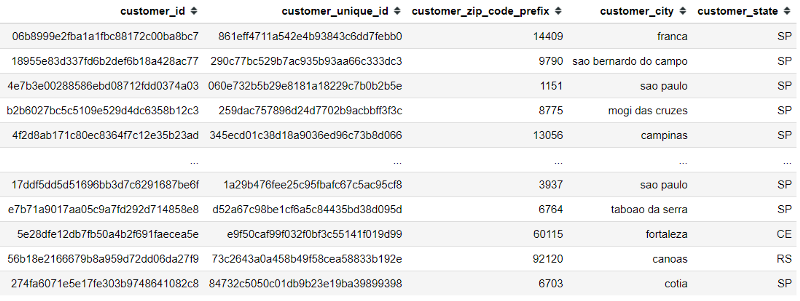
We can see the data contain a unique variable as identification called ‘customer_id’. This variable would be necessary when we want to use Featuretools because the Entity for Feature Engineering would use this unique variable as the grouping indicator.
Let’s take a look at the olist_order data as well.

We can see that the olist_order data contain the ‘order_id’ variable as the identification and also ‘customer_id’ variable to indicate who did the order.
For the last one, I want the data of the product, and the item ordered number, but because it is spread into two datasets, I would merge it into one. I would also drop some features we would not need and reset the index for the identification.
olist_item_product = pd.merge(olist_items, olist_product, on = 'product_id')olist_item_product.drop(['order_item_id', 'seller_id'], axis =1, inplace = True)olist_item_product.reset_index(inplace = True)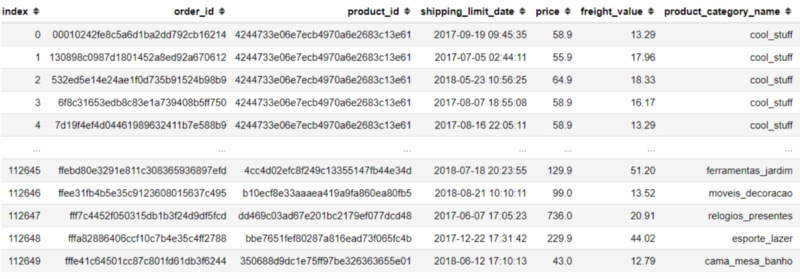
Now we have all the dataset we need. Let’s try to automate the Feature Engineering using Featuretools.
First, what we need to prepare are the Entities to perform DFS. So, what exactly we need to prepare in the Entities? As I mentioned before, Entities is a data frame representation. In the case of Entities, we would prepare a dictionary with the name of the Entity and the data frame with the identification.
The example of the entity is explained below.
#We prepare the dictionary with the specification is#'name of the entity' : (dataframe, identification)entities = { "customer" : (olist_customer, 'customer_id'), "order": (olist_order, 'order_id'), 'item_product':(olist_item_product, 'index')}Next, we need to specify how the entities are related. When two entities have a one-to-many relationship, we call the “one” entity as the “parent entity” and the “many” as the “child entity”. A relationship between a parent and child is defined like this.
#The relationship are defined by the entitiy name and the variable identification(parent_entity, parent_variable, child_entity, child_variable)#Examplerelationships = [('customer', 'customer_id', 'order', 'customer_id'), ('order', 'order_id', 'item_product', 'order_id')]In the above example, I defined the relationship between the ‘customer’ entity and ‘order’ entity with the ‘customer_id’ variable, which exists in both datasets.
Now is time to automate the feature engineering. It is easy to do; you just need to follow the below line. Note that this process would take some time, as the dataset is quite huge.
import featuretools as ftfeature_matrix_customers, features_defs = ft.dfs(entities=entities, relationships=relationships,target_entity="customer")From the above code, I would explain it a little bit. The method to create automation is the DFS, as I explained before. In this case, the DFS method mainly accepting three parameters. They are:
The entities
The relationships
The entity target
The first two parameters are the one we create before, and the last one “entity target” is the grouping for the aggregation. In our example below, let’s say we want to feature engineering based on the customer level.
After the process is done, we can see that we end up with many new features based on customer aggregation.
feature_matrix_customers.columns
As we can see in the above image, we right now ended up with 410 features as due to the automated feature engineering.
If you are curious how to read it some of the names of the columns, I would explain it a little. Take an example of SUM(item_product.price). This column means that it is the sum of the price from the item_product entity with the customer aggregate level. So, in a more human term, it is the total price of the item bought by the customer.
The next step, of course, develops the machine learning model with the data we just produce. While we have created the feature, would it be useful will certainly take more experiments. The important things are that we managed to automate the time-consuming aspect of model development.
Conclusion
Feature Engineering is an important aspect of developing a machine learning model as it is impacting our machine learning model. However, the process could take a long time.
In this case, we could use the open-source library called Featuretools to automate our Feature Engineering process.
Three terms we need to remember from Featuretools are Entity, Deep Feature Synthesis, Feature Primitives.
If you want to read more about Featuretools, you could visit the home page here.
I hope it helps!