


Explainable RAG for More Trustworthy System
NBD Lite #51 Evaluate both the retrieval and generation in systematic ways

All the code used here is present in the RAG-To-Know repository.
We have learned that retrieval-augmented generation (RAG) is a system that combines data retrieval techniques with LLM-based generation. This means that the RAG system produces output based on the context provided by both its retrieval and generation components.
In the production system, the user will use our system and act based on the output. However, how much could we trust the RAG system? This is a question we need to explore before we push the system into production or even when we re-evaluate the system.
In the previous article, we discussed a CRAG technique that could improve the RAG result, but the result will still need to be evaluated.

In this article, we will explore how to evaluate both the retrieval and generation parts for explainability purposes. In general, the system will follow the diagram below.
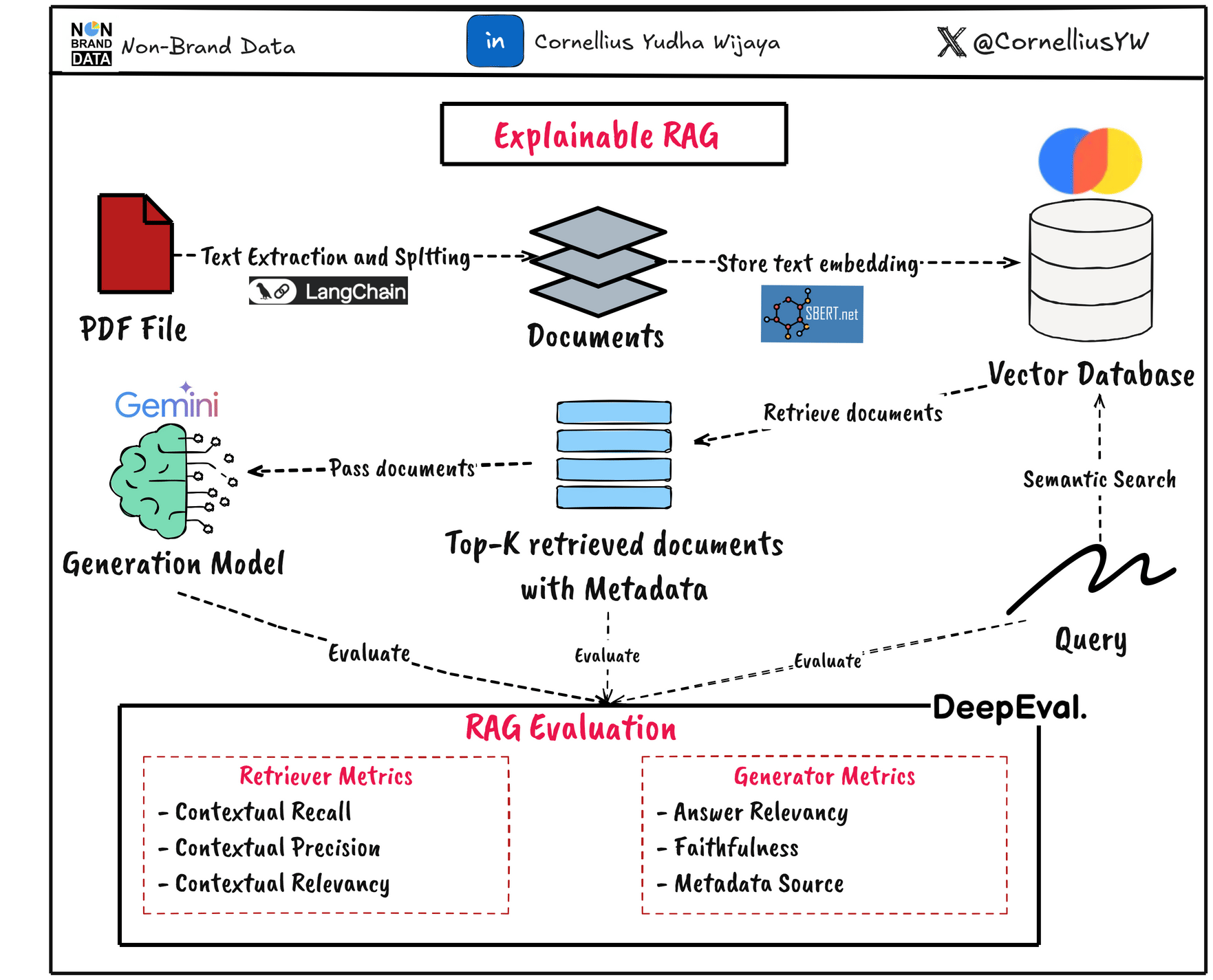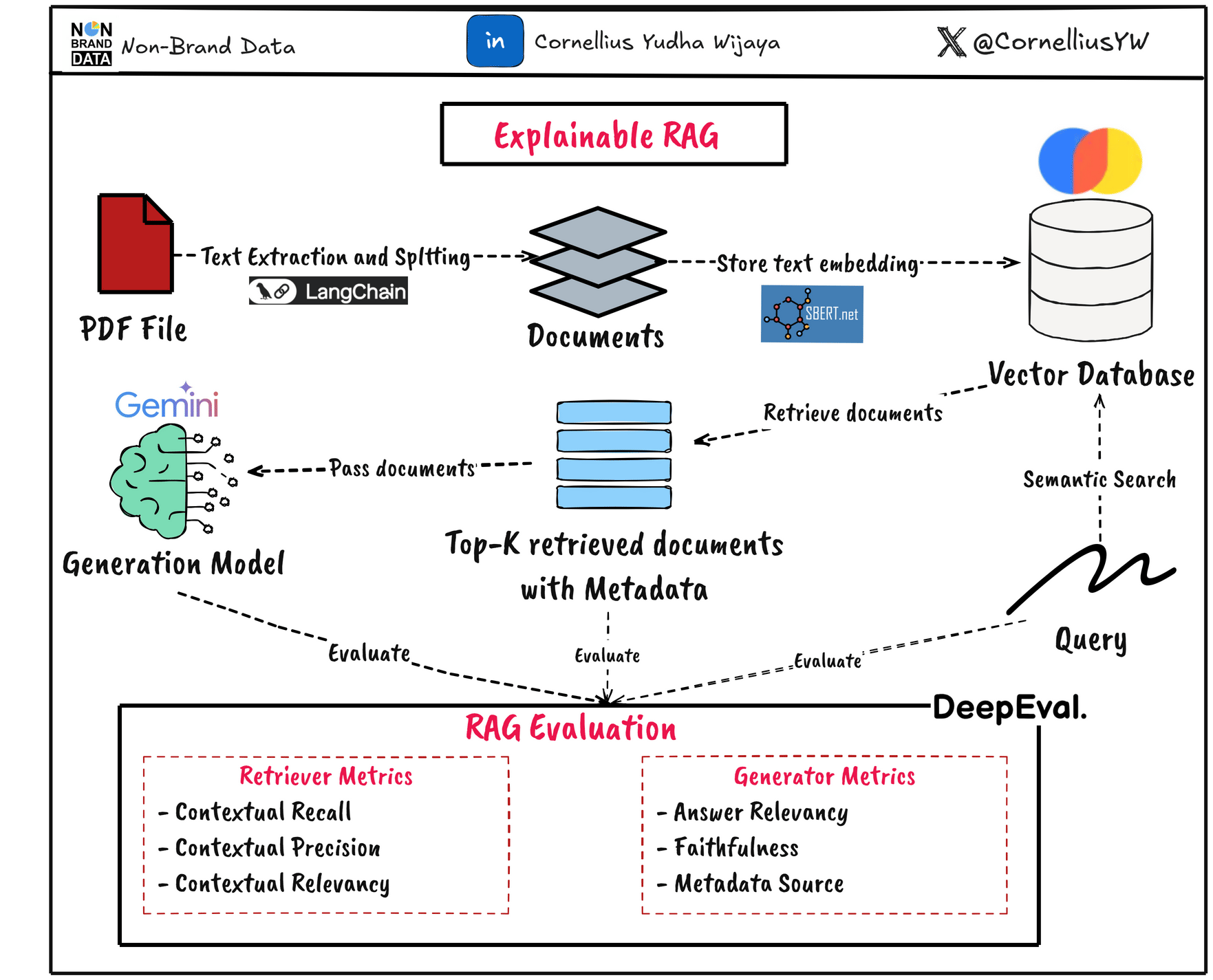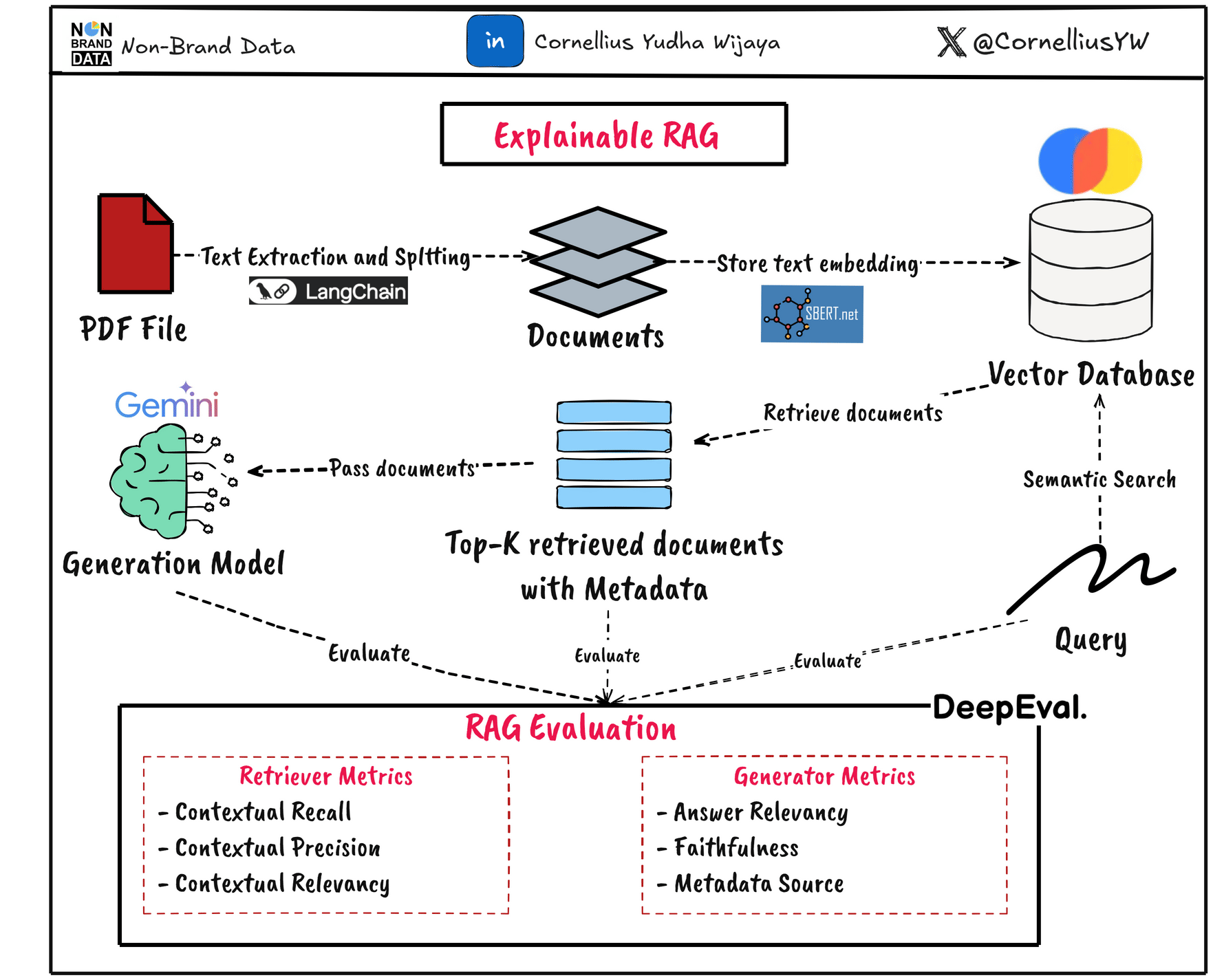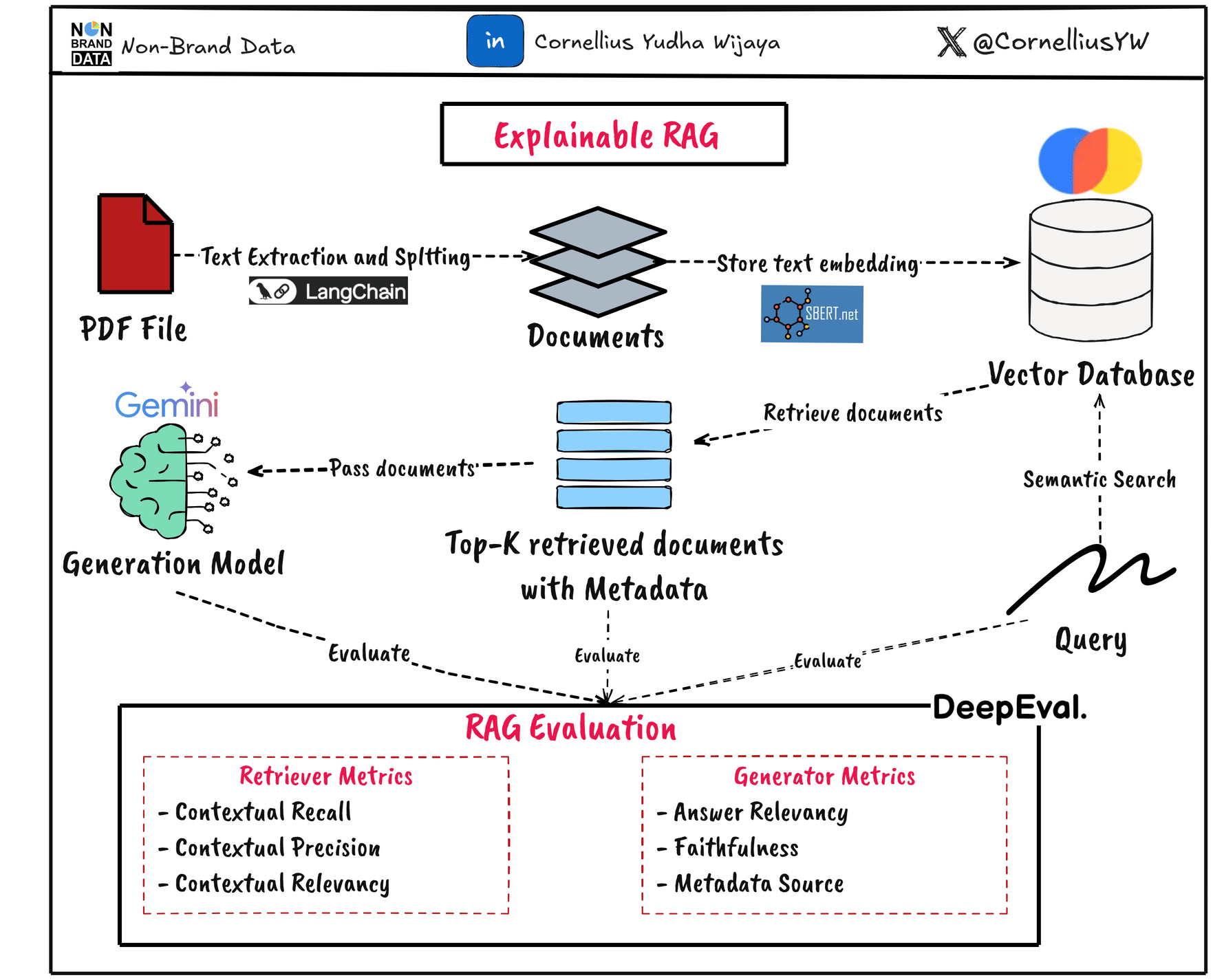
Introduction
As mentioned above, RAG is a technique that provides output based on the relevant context coming from external knowledge and the generation of LLM. This is why RAG is strong enough to respond outside of its training data.
There are two important components in the RAG system: the Retriever and the Generator.
Because the RAG output quality relies on both the retriever and generator, we need to evaluate the components separately and provide explainability to increase the system's trustworthiness.

To add to the explainability of our system, we can use several metrics to evaluate both the retrieval and generator parts. We can use LLM-as-a-Judge to help, but we can extend them to evaluation metrics to add numerical representation.
In this article, we will execute the evaluation using the DeepEval framework. They are libraries that provide a lot of methodology and techniques for Generative AI evaluation, and that’s including the RAG system.
Evaluating Retrieval
DeepEval provides retrieval evaluation metrics, including:
Contextual Precision: Evaluate whether the reranker model in your retriever ranks more relevant nodes higher than irrelevant ones.
Contextual Recall: Evaluate whether the embedding model in your retriever accurately captures and retrieves relevant information based on the input context.
Contextual Relevancy: Evaluate whether the text chunk size and top‑K parameter in your retriever enable it to retrieve information with minimal irrelevancies.
These three metrics are necessary to explain what happens in our retrieval, as the information will ensure that we are feeding appropriate data to the generator.
Evaluating Generation
DeepEval also offers two evaluation metrics to evaluate generations part:
Answer Relevancy: Evaluate whether the prompt template in your generator effectively instructs your LLM to produce relevant and helpful outputs based on the retrieval context.
Faithfulness Metric: Evaluate whether the LLM used in your generator outputs information that avoids hallucinations and does not contradict any factual information presented in the retrieval context.
In addition, I would like to add another thing to improve the Generation output, which is:
Metadata Source: Additional information to understand where the retrieved information is coming from.
All of this information will become important if we want to have an explainable RAG.
Let’s see how they are performing in action with Python code implementation.
Building Explainable RAG
In the next step, we will try building an explainable RAG with the evaluation metrics using DeepEval. The code will not show things from scratch. Instead, we will build on top of the simple RAG system we created previously.
Let’s start by building the function to perform the retrieval process with the reranking system.
from tqdm import tqdm
# Function to evaluate relevance using Cross-Encoder
def evaluate_context_cross_encoder(query, context):
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
score = cross_encoder.predict([(query, context)])[0]
return score
# Function to rerank documents using Cross-Encoder
def rerank_with_cross_encoder(query, documents):
scores = []
for doc in tqdm(documents, desc="Reranking documents with Cross-Encoder"):
score = evaluate_context_cross_encoder(query, doc)
scores.append(score)
# Sort documents based on scores
reranked_docs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return reranked_docs, scores
def semantic_search(query, top_k=2):
# Generate embedding for the query
query_embedding = text_embedding_model.encode(query)
# Query the collection
results = collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=top_k
)
rank = [i+1 for i in range(top_k)]
df_retrieved = pd.DataFrame([], columns=['original_documents', 'rank'])
df_retrieved['original_documents'] = results['documents'][0]
df_retrieved['source'] = [metadata['source'] for metadata in results['metadatas'][0]]
df_retrieved['rank'] = rank
# Perform Cross-Encoder reranking
cross_encoder_reranked_docs, cross_encoder_scores = rerank_with_cross_encoder(query, results['documents'][0])
df_retrieved['ce_documents'] = cross_encoder_reranked_docs
df_retrieved['ce_scores'] = cross_encoder_scores
df_retrieved = df_retrieved.sort_values(by ='ce_scores', ascending = False).reset_index(drop =True)
df_retrieved['ce_rank'] = [i+1 for i in range(top_k)]
return results, df_retrieved
top_k = 20
# Example query
query = "What is the insurance for car?"
results, df_retrieved = semantic_search(query, top_k = top_k)The function above will show all the retrieved chunks with the reranking result as well.

Next, we will build the evaluation system for both retrieval and generator using DeepEval. We will use all the metrics we have explored previously.
DeepEval will require various inputs for the test evaluation to work properly, including:
The user query
The generated output
The expected output based on the query
All the retrieved context
Once you have all of them, we can structure it and put it in the code.
In the code below, we prepare functions that can receive all the retrieved data frames we have previously and provide evaluation results.
# Set up LiteLLM with Gemini and Evaluation with DeepEval
def generate_response_and_evaluation(query, df, expected_output = "",documents_origin = 'ce_documents', document_metada ='source',top_k_context = 5):
# Prepare Retrieval and Generation evaluation
contextual_precision = ContextualPrecisionMetric()
contextual_recall = ContextualRecallMetric()
contextual_relevancy = ContextualRelevancyMetric()
answer_relevancy = AnswerRelevancyMetric()
faithfulness = FaithfulnessMetric()
# Retrieve the top results from semantic search
search_results = semantic_search(query)
retrieved_context = list(df.iloc[:top_k_context].apply(lambda row: f"{row[documents_origin]} - Source: {row[document_metada]}", axis=1).values)
context = "\n".join(retrieved_context)
# Combine the query and context for the prompt
prompt = f"Query: {query}\nContext: {context}\nAnswer: \nSource:"
# Call the Gemini model via LiteLLM
response = completion(
model="gemini/gemini-1.5-flash", # Use the Gemini model
messages=[{"content": prompt, "role": "user"}],
api_key= GEMINI_API_KEY
)
generated_output = response['choices'][0]['message']['content']
# Prepare the test case
test_case = LLMTestCase(
input=query,
actual_output=generated_output,
expected_output=expected_output,
retrieval_context=retrieved_context
)
# Evaluate the test case
contextual_precision.measure(test_case)
contextual_recall.measure(test_case)
contextual_relevancy.measure(test_case)
answer_relevancy.measure(test_case)
faithfulness.measure(test_case)
eval_res = {'contextual_precision_score': contextual_precision.score, 'contextual_precision_reason': contextual_precision.reason,
'contextual_recall_score': contextual_recall.score, 'contextual_recall_reason': contextual_recall.reason,
'contextual_relevancy_score': contextual_relevancy.score, 'contextual_relevancy_reason': contextual_relevancy.reason,
'answer_relevancy_score': answer_relevancy.score , 'answer_relevancy_reason':answer_relevancy.reason,
'faithfulness_score': faithfulness.score, 'faithfulness_reason': faithfulness.reason}
df_result = pd.DataFrame(eval_res, index = [0])
df_result['generated_output'] = generated_output
# Extract and return the generated text
return df_result
# Generate a response using the retrieved context
query = "What is the insurance for car?"
expected_output = "Car insurance is a contract that financially protects you from losses due to vehicle accidents, theft, or damage."
response = generate_response_and_evaluation(query, df_retrieved, expected_output)The response will look like the following data frame.

For example, the Contextual Precision score is 0.45 for the following reason:
The score is 0.45 because while the second and fifth nodes are relevant to car insurance and offer substantial information like 'auto liability requirements' and 'basic auto insurance policy,' they are not ranked at the very top. The first node, which is less relevant as it focuses on 'financial cushions and surplus lines,' is ranked higher. Similarly, the third and fourth nodes, discussing topics like 'self-insurance' and 'business auto insurance,' appear before or between more pertinent details. The presence of these less related topics being ranked higher affects the precision score.As contextual precision evaluates the whole reranking system, it provides a score and reasons why it’s quite low.
We can go through each score one by one and gain explainability for each part of the system.
That’s all for now. You can check out the RAG-To-Know repository for the whole code of Explainable RAG implementation.
Is there anything else you’d like to discuss? Let’s dive into it together!
👇👇👇
