


Implement Cost-Sensitive Learning for Imbalanced Classification Problems
Improve your classification model performance for the imbalance problem


Whenever we develop a classification machine learning problem, we evaluate the model's performance to see if it would perform well in a real-world situation.
In the classification model, we would compare if the prediction from the model is assigned correctly to the test data and calculate the evaluation metrics from there. In general, we want to minimize the misclassification as much as possible.
However, not all misclassifications are created equally. Depending on the use cases, certain misclassifications might cost more.
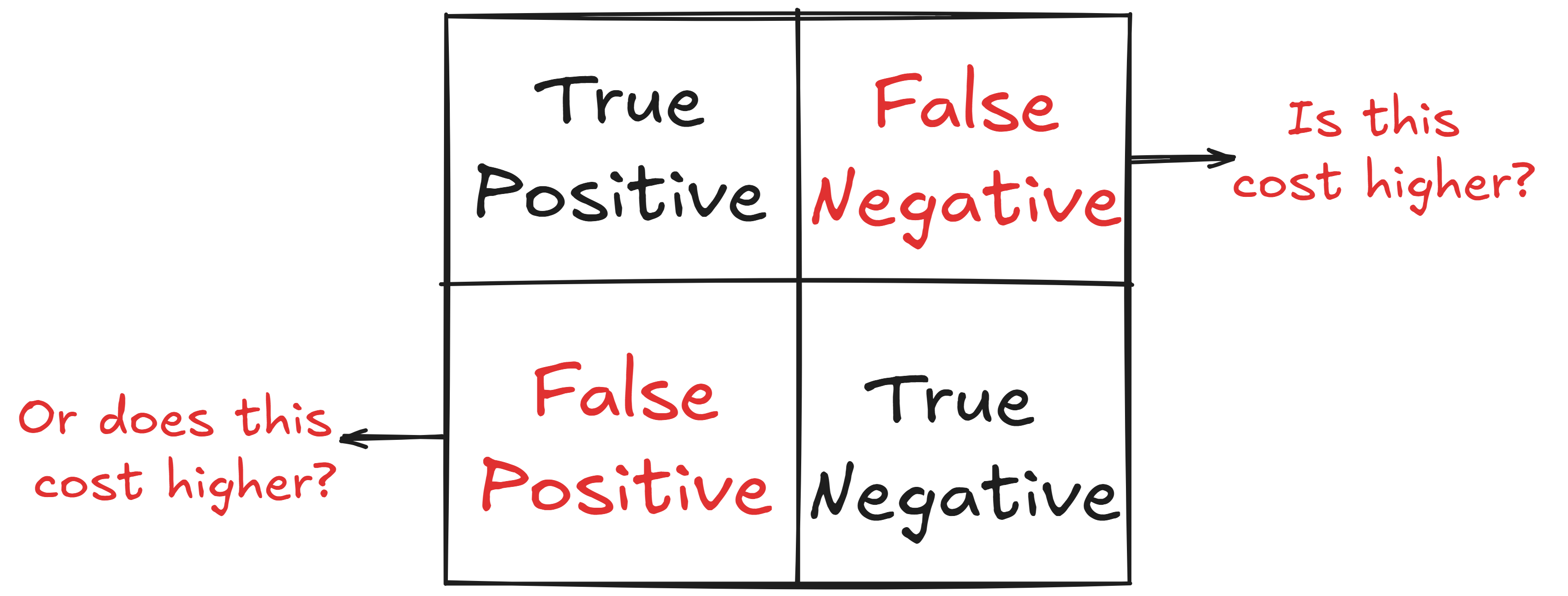
For example, misclassifying a patient with cancer as healthy (False Negative) may cost more than misclassifying a healthy patient as having cancer (false positive).
In an imbalance case, the classifier often has difficulty predicting one of the classes. The more severe the imbalance cases were, the harder the classifier could predict. Sadly, many important use cases, such as cancer detection or fraud management, were imbalance classification cases.
With the costly misclassification in the imbalance case, Cost-Sensitive learning can help the model focus on correctly classifying the minority class, which is often more critical in imbalanced datasets.
In this article, we will explore how to implement Cost-Sensitive Learning to improve performance in imbalance cases.
Let’s get into it.
Keep reading with a 7-day free trial
Subscribe to Non-Brand Data to keep reading this post and get 7 days of free access to the full post archives.