
Important GIT Commands For Data Scientist
Learn important version-control basic for Data Scientist

Learn important version-control basic for Data Scientist

As a Data Scientist in a business company, we would work independently and with a team. This is unavoidable, as many works are better solved with a team behind.
There are usually problems with data science teamwork, mainly the historical workflow and the programming code conflict. This is why we need a version-control to have better collaboration between teams.
Now, what is version-control? Version-control is a concept of managing changes in source codes, files, and directories. One popular version-control system out there is GIT.
While a software engineer often uses version-control, data scientists need to know version-control to some degree. Collaboration is, in fact, the main selling point of why data scientists using version-control. Without it, our work would be a mess.
For the reason above, I want to show a few important terms and commands from Git that everyone should know.
Git
Just like I mentioned above, Git is a free and open-source distributed version control system. Git is used by many companies worldwide and consider a staple in everyday programming life.
For this article preparation, we would need two things:
You might wonder why we would use GitHub; this is because we need the workplace to show how Git works in the collaboration environment, and GitHub provides us that.
Now, let’s try a few commands we could do with Git.
Repository
In your GitHub account, you would find a button to create a new repository, and it would show some form that looks like the below picture.
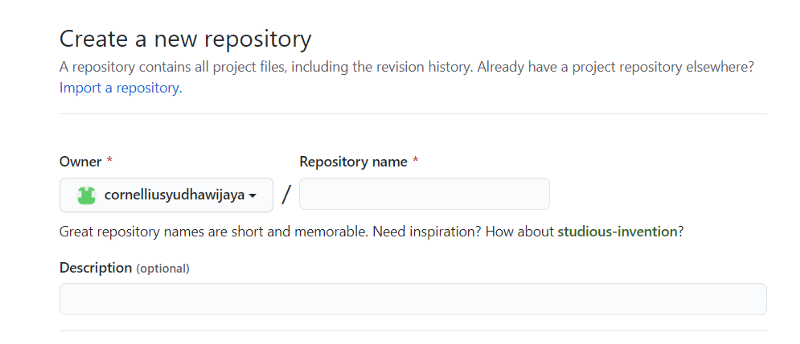
Although, what is a Repository?
While we manage our project using Git, there are two things that Git would manage:
Your file (script, model, etc.) and the directories, and
Git Information to maintain historical change within your project over time.
When we combine both of the pieces above, we would have what we called Repository or Repo.
Now, let’s try to create your own Repository in the GitHub, which should look like this.

After a new repo, we would try to utilize the Git command for you to try this time.
GIT Command
Before we start, let’s try to create a new folder in your local drive. It could be anywhere you want. Then inside the new folder, try to have any file you want; In my case, it is a jupyter notebook.

After that, try to right-click in your new folder and choose the “Git Bash Here.”

There would be a command prompt shown up, for your first time, there might be credential information you need to input. Just follow the step, and we are ready to start.
1. Git init
Every hero has a start, and so does Git. When you are using Git for version control purposes in your local area, you need to set up the environment first.
Git init was used to do that. Try to run git init in your command prompt where the directories are in your intended folder. There should be a message that looks like this.

Now we already set up the environment or our repo in the local folder that ready to accept any git command.
2. Git status
The next step we would do is checking our git environment status. What status here means is checking whether there is any file in the staging area or not.
So, what is the staging area? This is basically an area where you put or tracked your files before making any changes to them. This is where the files are sorted if you want to send it, removed it, or add any new files. This is called the staging area because after this area, it would be permanent.
To try the command, we can run git status in our command prompt. It should show something like this.
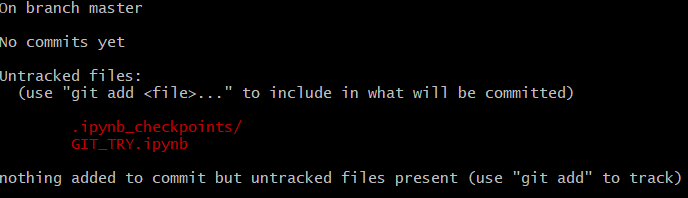
With this command, the status of our file is shown. We only have untracked files, which means this file is not yet added to the staging area. So, what to do next? We need to add these files to the staging area.
3. Git add
Just like you can see above, we add the files to the staging area by running the git add command. Specifically, we would need to type git add <filename> where <filename> is the name of the file you want to add to the staging area.
It would be a hassle to add manually every single file name. Imagine if you have a thousand files in the local folder and how long it would take to input every file. In this case, we can add all the file inside the folder into the staging area by run git add . in the command prompt.
When you have finish add every file into the staging area, try to run the git status once more. It should look like this.

Every file in the folder is now in the staging area.
4. Git commit
When we already have all our files in the staging area, we need to commit if we want the staging area files are the one we want.
If you are sure, then we need to run the git commit command. The complete command is git commit -m "<your comment>" where <your comment> is your log messages or some simple note for you to remember.
Let’s try to run the git commit. When it is done, it should look like this.

In my folder, there are two files, so that is why there are two files committed.
5. Git log
If you need to see every commit you have done in your repo, we can run git log. It could show your repository's history of commits. As the author, there should be important information, the commit key, commit date and log message.
6. Git push
When you create a new repo in the GitHub, you would see a series of messages like this.

You could run the command from the beginning to the end, but the only important part right now is to learn what is git push.
This git pushcommand that puts your repo from your local to the Git Hub's online repo. It just likes the name, push the repo.
In this step, I would skip running the git branch -M main command as we don’t need it right now.
What you need to run first is the git remote add origin <your git domain> where <your git domain> is the address of your git repo.
So, what we did in the command above is creating a variable called ‘origin’ with the variable object are <your git domain>.
When you had created the ‘origin’ variable, we need to push our local repo to the ‘origin’ repo. What we need to do next is run the git push -u origin master. This command would push our local repo (called master) to the ‘origin.’ After it finishes, it should look like this.
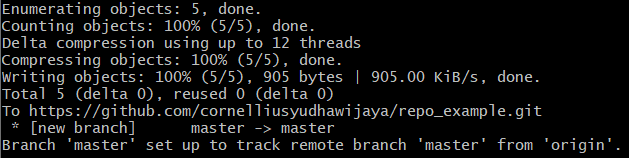
And your GitHub repo should look like this.

We know already have track our historical version of our files and data using Git, and the history is also stored in the local repo in the GitHub.
Conclusion
Git is important for Data Scientist because With data science teamwork, there are usually problems; mainly the historical workflow and the programming code conflict. Git could help us to solve these problems.
In this article, I have introduced you the basic Git commands, which are:
Git init
Git status
Git add
Git commit
Git log
Git push
I hope it helps!