


Interesting Research: OneLLM Unified Eight Modalities into One
The one framework that align all modalities into language


Multimodal LLM is a model that can receive input data from multiple forms (text, image, audio, etc.), and could provide the form of textual language as output. Basically, LLM could understand any data it provides.
One research I found interesting is the latest research by Han et al. (2023), which provide a unified LLM framework from various modality. I feel it’s shown promising results and useability in the future.
So, how does it work? Let’s get into it.
OneLLM Introduction
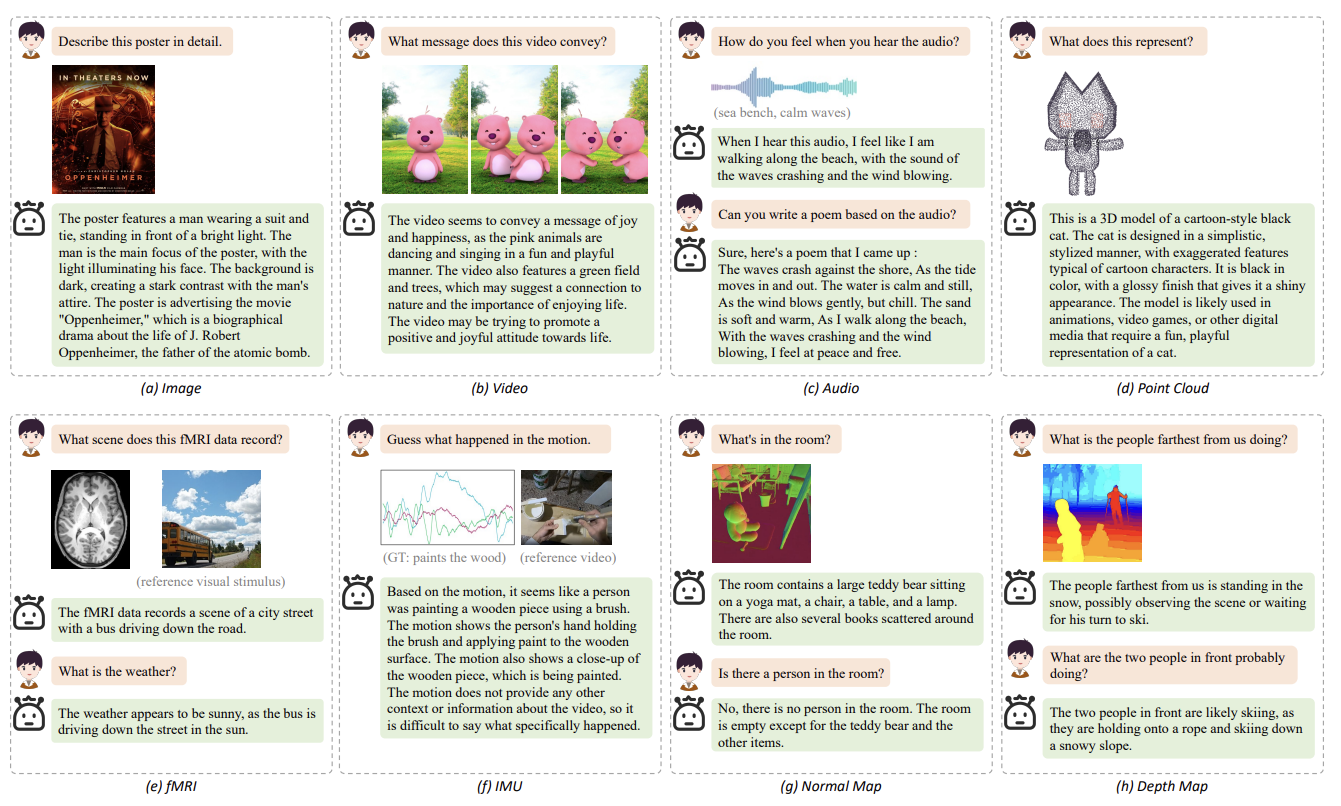
The paper introduces OneLLM, a novel Multimodal Large Language Model (MLLM) designed to integrate eight different modalities with language effectively using a unified framework. We can see the data that OneLLM could accept in the following image.

OneLLM supports eight different modalities compared to many previous models, which is three. An example of the model input and the output can be shown in the image below.
Unlike traditional MLLMs that use modality-specific encoders, OneLLM employs a unified multimodal encoder and a progressive multimodal alignment pipeline.
This alignment process begins with an image projection module that connects a vision encoder to the Large Language Model (LLM). This is followed by the creation of a Universal Projection Module (UPM), formed by combining multiple image projection modules with dynamic routing.
Subsequently, the UPM is used to align additional modalities to the LLM progressively. Furthermore, to maximize OneLLM's capabilities in following instructions, a comprehensive multimodal instruction dataset comprising 2 million items from various modalities like image, audio, video, point cloud, depth/normal map, IMU, and fMRI brain activity was curated.
Overall, the OneLLM Architecture can be shown in the image below.

OneLLM has been evaluated across 25 diverse benchmarks, covering tasks such as multimodal captioning, question answering, and reasoning, demonstrating outstanding performance. OneLLM has been shown to outperform existing methods in video-text, audio-video-text, audio-text, and point-clod-text tasks, which has shown great potential.
Trying out OneLLM
Currently, the OneLLM researcher has released the inference code and the model weights in their GitHub Repository. You can install the packages by using the following code.
First, you need to clone the repository.
git clone https://github.com/csuhan/OneLLM
cd OneLLMThen, you could install the packages.
conda create -n onellm python=3.9 -y
conda activate onellm
pip install -r requirements.txt
# install pointnet
cd model/lib/pointnet2
python setup.py installWe can also use the HuggingFace Demo to try out the model. For example, I tried the model with an image sample.
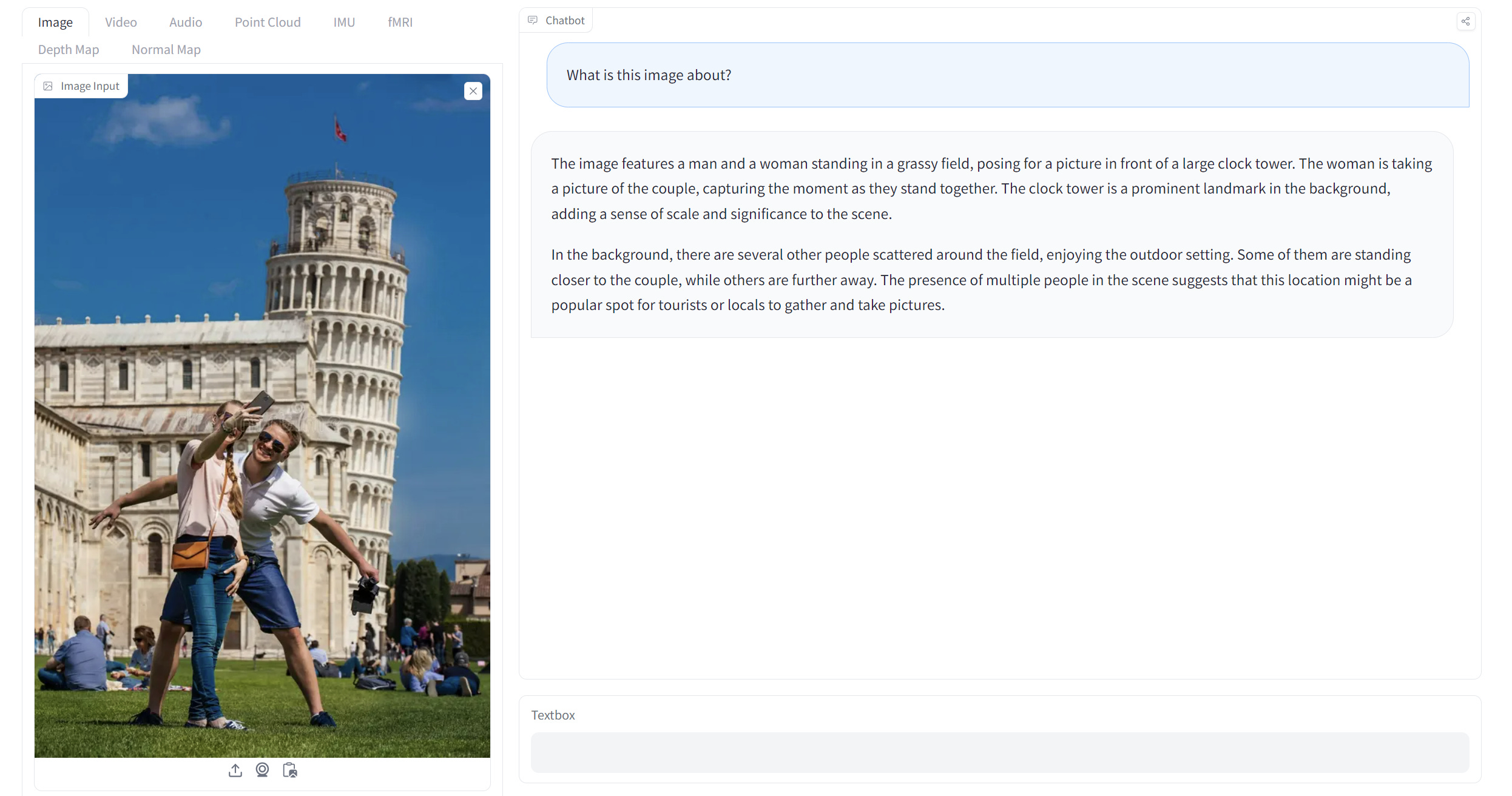
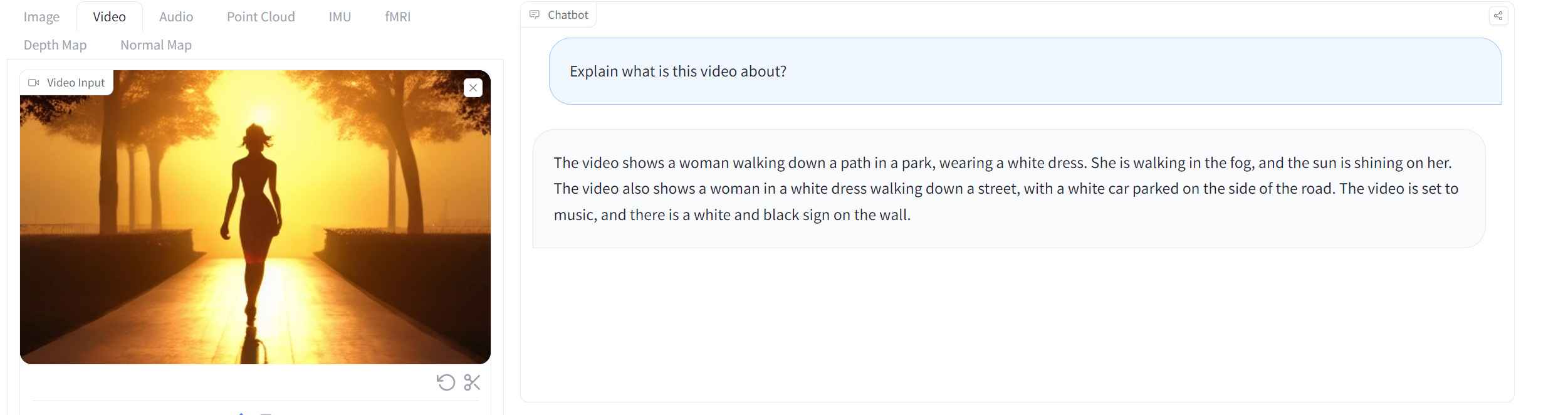
The result showed a great understanding of the image input I give. I can also try Video data as an input.
Additionally, I can use the example point cloud data as an input.
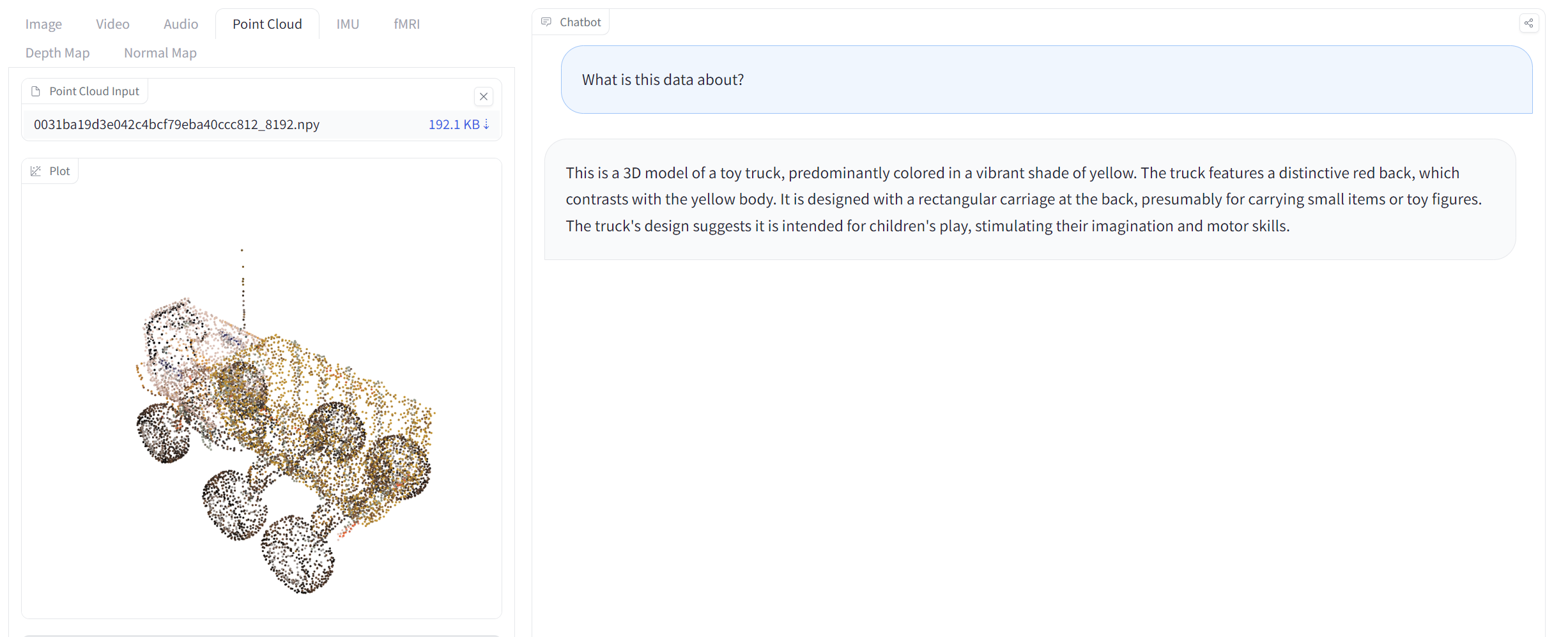
There are many possibilities now with the OneLLM, and I can see that this model would be important in the future.
I hope it helps!


Thank you, everyone, for subscribing to my newsletter. If you have something you want me to write or discuss, please comment or directly message me through my social media!