
Label Propagation in Hybrid Models - NBD Lite #40
Harnessing the Power of Semi-Supervised Learning


There are cases in our machine learning project where we only have limited labeled data, but we have much more unlabelled data to process.
In the case above, we can employ Semi-Supervised Learning (SSL).
SSL is a technique where we use the model to train the labeled data to learn their pattern and use the unlabeled data to refine or expand the pattern.
One of the SLL techniques is Label Propagation, in which we spread (or "propagate") labels from labeled data points to unlabeled data points.
So, how do they work? And why should you know about Label Propagation?
Let’s explore it together!
Label Propagation
As mentioned above, Label Propagation is a technique to spread the labels to unlabeled data.
Label Propagation technique works based on the idea that data close to each other in feature space should have similar labels.
The idea above is based on the manifold assumption in machine learning, where data points that lie on the same manifold (or cluster) tend to have the same label.
If we try to visualize the process, it would be similar to something like below.

We have limited labeled data and a lot of unlabeled data. Based on the closeness, we would try to label the unlabeled data properly.
In more detail, Label Propagation is divided into a few steps:
Graph Construction is where the algorithm builds a graph where each data point is connected to others based on similarity.
Label Initialization occurs. In this case, the labeled points keep their initial labels. Then, the unlabeled points are initially set with no label or are labeled based on a weak initial guess (often random).
Propagation is done in the following details:
Each labeled node’s label influences its neighbors. Unlabeled nodes adjust their labels based on the labels of neighboring nodes.
For each unlabeled node, the label is updated by a weighted average of its neighbors’ labels.
This step is repeated iteratively, with labels spreading through the graph until all nodes’ labels stabilize (convergence).
Lastly, Convergence happens. The algorithm stops when label changes between iterations become negligible or a maximum number of iterations is reached.
That’s the basic explanation of Label Propagation. Let’s try out the Python implementation.
First, let’s generate the synthetic data.
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import LabelPropagation
import matplotlib.pyplot as plt
X, y = datasets.make_moons(n_samples=1000, noise=0.15, random_state=42)We will generate 1000 samples of crescent-shaped moon data with some noises.
Then, we will set the label and unlabeled data, with the unlabeled data representing the majority (90%) of the data.
labels = np.copy(y)
num_labeled_points = int(0.1 * len(labels))
labels[num_labeled_points:] = -1 With the data ready, we will fit the Label Propagation model. We will use the Radial Basis Function (RBF) kernel, which is the similarity function that measures how close two data points are. The gamma parameter in the RBF kernel controls the "spread" or "sensitivity" of the kernel.”
label_prop_model = LabelPropagation(kernel='rbf', gamma=20)
label_prop_model.fit(X, labels)With the Label Propagation finish fitted, we can acquire the predicted labels.
predicted_labels = label_prop_model.transduction_Lastly, let’s visualize the result of Label Propagation compared to the initial state.
plt.figure(figsize=(12, 8))
# Colors for each class
colors = ['#4CAF50', '#FF9800']
for label in np.unique(predicted_labels):
plt.scatter(X[predicted_labels == label][:, 0], X[predicted_labels == label][:, 1],
color=colors[label], marker='o', edgecolor='k', s=30, label=f'Predicted Label {label}', alpha=0.8)
plt.scatter(X[labels == -1][:, 0], X[labels == -1][:, 1], c='gray', marker='x', label='Unlabeled Data', s=50, alpha=0.6)
# Add title and labels
plt.title("Semi-Supervised Learning with Label Propagation")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.legend(loc='upper right')
plt.show()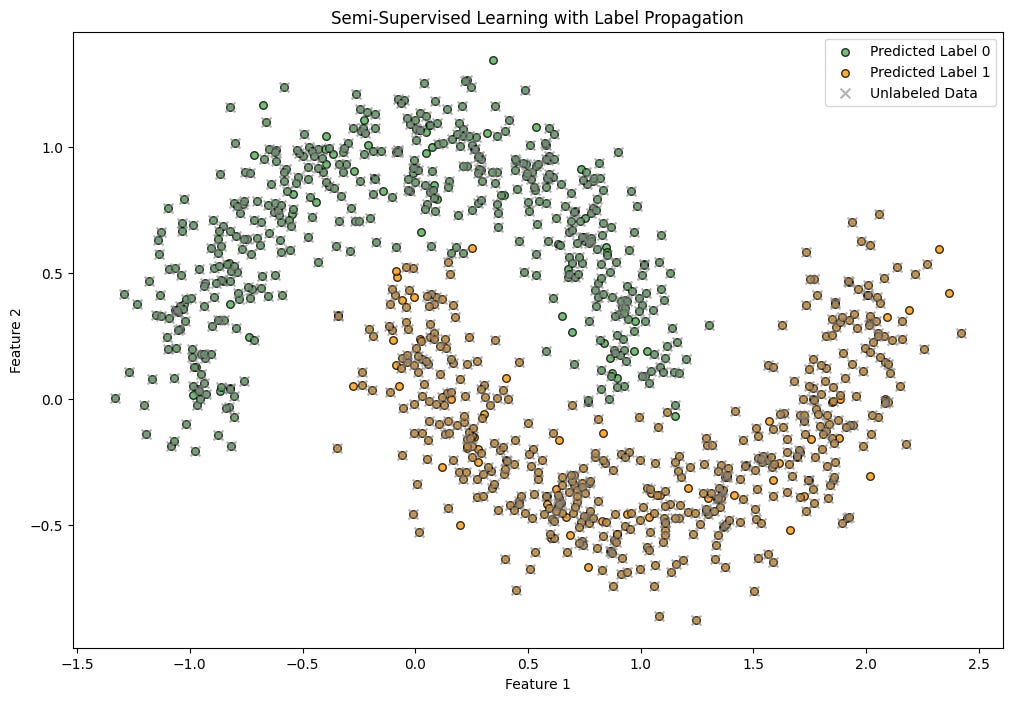
The plot above shows that Label Propagation successfully clusters a crescent-shaped dataset by spreading limited labels across similar unlabeled points.
That is the simple explanation of Label Propagation.
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
